HADOOP
Alright this is a small post Im creating here just as preparatory post for HADOOP and MAP-REDUCE in the coming post . So lets get started.
What isss HDFS ? HDFS stands for hadoop distributed file system . So the file system came into being when amount of data being stored and processed and used increased exponentially between late 1990’s and early 2000 . This was the time when search engines were being developed to quantify and rank the data and for that particular process huge huge amount of data was needed to be read for various operations .
The difficulty ? see back in the days when data was limited and could be stored onto drives which had a size less 1024 mb the speed at which data was being accessed was in MB/s which meant that data could easily be read off the drives in matter of minutes .
But as the data started to scale to terabytes and petabytes the rate at which the data was being accessed was not able to catch up . That means that at a transfer speed of 100mb/s we were trying to process terabytes of data which was not feasible at all considering the time it would take .
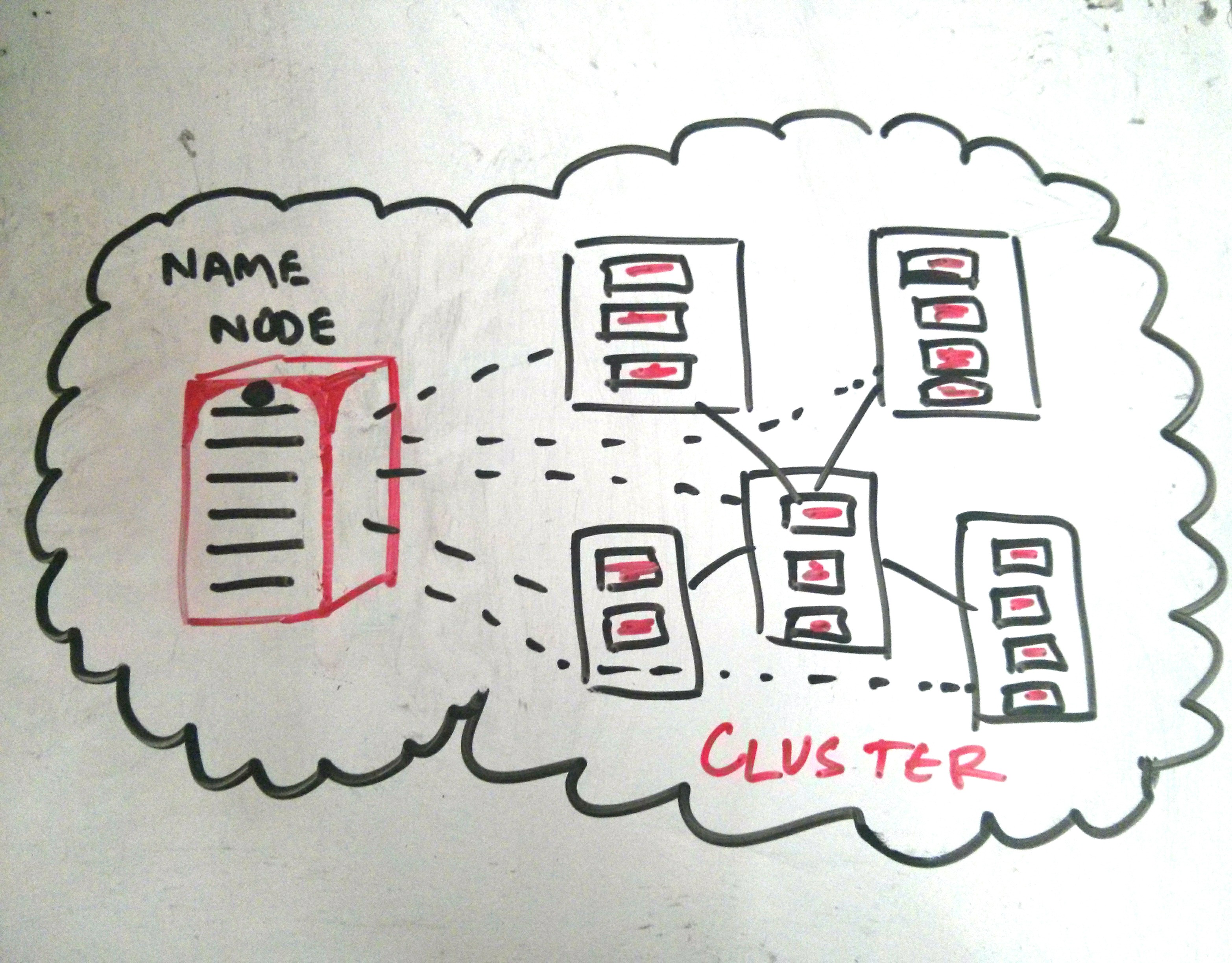
In order to solve this problem HDFS was developed . Now HDFS provided a way to distribute Data across multiple servers or connected computers in chunks of size 64MB.
These Chunks are called Blocks. Check out the classy diagram I drew B) All vintage and stuff.
 Each machine that the data is sent to runs a separate operating system and these machine, known as nodes , are connected with each other through Super fast LAN or local Area Networks.These computer together are known as a cluster.
Each machine that the data is sent to runs a separate operating system and these machine, known as nodes , are connected with each other through Super fast LAN or local Area Networks.These computer together are known as a cluster. 
In order to prevent losing the data when a node or computer fails or data access gets interrupted , 3 copies of these small chunks or blocks are kept on different machines or nodes .So If while processing the block 1 node 1 fails the node 2 which has another copy of block 1 can be used and process can be continued without much problem . This make HDFS system robust to data loses due to node failures.
Now so that we know which node each chunk or block is we have another Node or Machine which keep the track of it . This machine is known as Name Node. These are the main components or fundamentals of HDFS system and lets move to MAPREDUCE.
MAPREDUCE
If we want to process this data stored in HDFS we use a paradigm or method called mapreduce . Google was the first know company to have used mapreduce in its work .Map reduce has two important phases
- 1st Mapper phase
- 2nd Reducer phase
I am going to try and explain it using an analogy .
Think about the current situation where world cup is happening in brazil . Now organisers want to find out attendance of people and which country they belong to . So the problem is there huge crowd waiting to get into the stadium = huge amount of data.

Now if everyone is trying to get in from one single entry point it will lead to chaos much like loading all the data onto one machine or node. If now only one counter is trying to count the number of people from different country it will be a very messy and slow process.

So what we do is distribute the data like in HDFS system and distribute the crowd onto different counters like the blocks of data onto different machines.

Now that the crowd is controlled and the flow is good we send a guy onto each counter to do the counting job done and we will call this guy a MAPPER . A mapper is a programme that is sent to different machine where the data exist.
Now what this guy mapper does is start counting the number of people from different countries. Each counter mapper maintains a different record. After all the mappers are done with the process they send the record in sorted order to another guy called REDUCER as a list of counts from different counters . The List received by the Reducer looks something like this .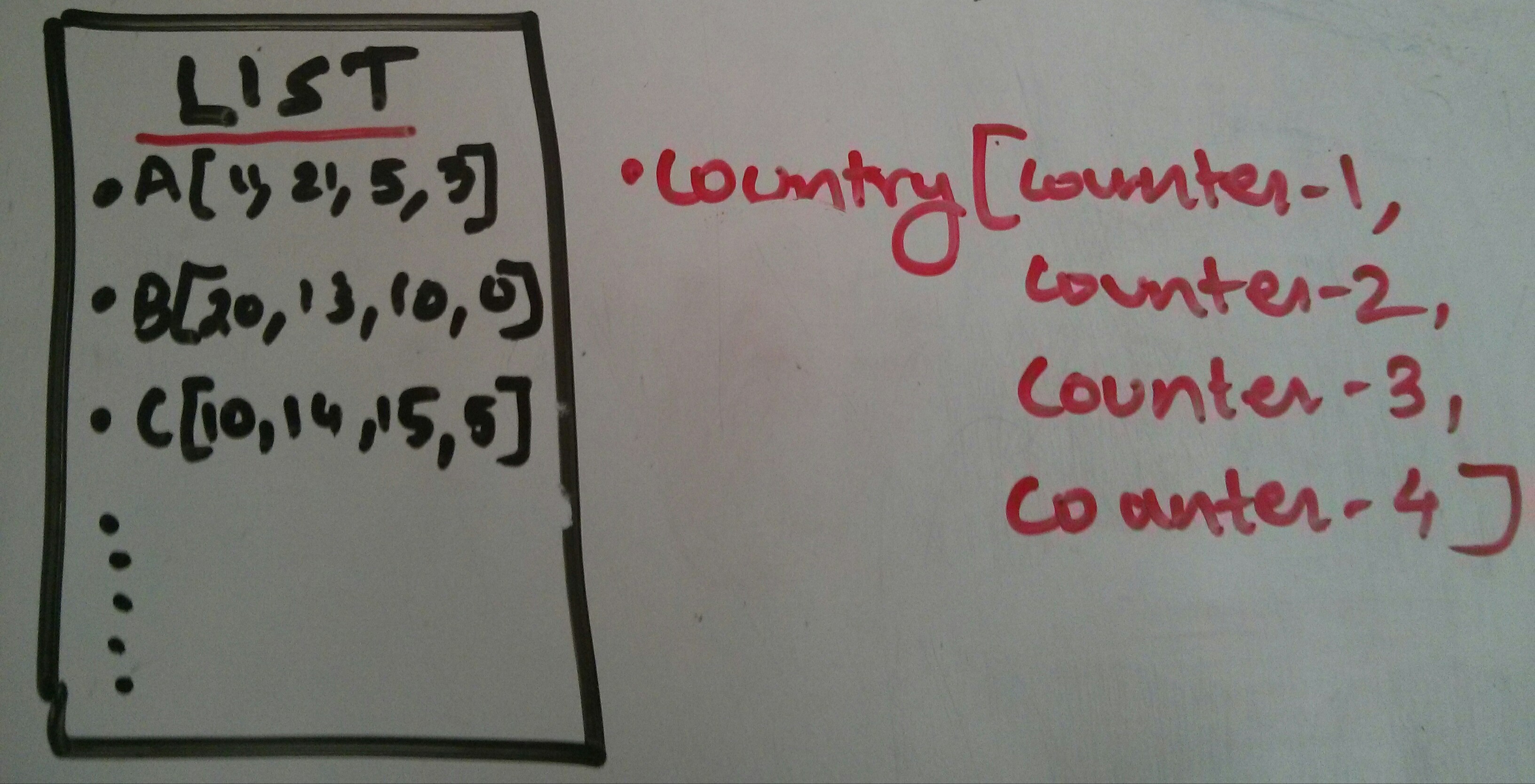 The Reducer now goes through the list .
The Reducer now goes through the list .
The reducer goes through the list adding the counts from each country and produces a final result which is the desired value of count. Thats it thats how map reduce works .
Thats it thats how map reduce works .
For more in depth and technical know how please check the following link
Now I’ll be posting about how to write a map reduce script in python in the coming week . This is just to get you started with the concept. 🙂 later!! please do like and subscribe and share. Those drawings took time 😛 .



Nice Article .. good analogy !!
LikeLike
I’m glad that you like it Seerangan. 🙂
LikeLike